Node.js Security Unleashed: Your Ultimate Defense Guide (2/7)
Part 2 - How to prevent Server-Side Request Forgery (SSRF)

Devoted Web Solutions Architect, Software Engineer and Technical Writer from Kharkiv, Ukraine. Areas of focus: Front and Back End development, DevSecOps, Computer Networking and Security, Dev.
A Preface
Nowadays, everyone acknowledges that there exists a plethora of possible attacks and exploits, each capable of employing diverse approaches to compromise a targeted system. Thankfully, a significant portion of them derives from the well-established concepts and relies on widely recognized patterns.
Therefore, such threats, though each having its own peculiar characteristics, can still be classified based on their shared traits. By identifying these commonalities, the development community managed to elaborate a comprehensive suite of effective countermeasures against them.
Throughout this article series, we will highlight seven signature attack patterns that we should be concerned about when safeguarding our Node.js applications.
!!! Disclaimer !!!
The information provided in this article is intended for educational purposes only. Readers are encouraged to consult with qualified cybersecurity experts and adhere to their organization’s security procedures when addressing the mentioned attacks. Neither the author nor the hosting platform is responsible for any actions taken by individuals or organizations based on the information contained herein.
Please be prudent, and use the provided information solely with good intentions.
Series Agenda.
2/7: ⠀Server-Side Request Forgery (SSRF) — you are here.
5/7: ⠀SQL Injections (SQLi).
7/7: ⠀OS Command Injections.
How to prevent Server-Side Request Forgery (SSRF) in Node.js
Introduction
Greetings, dear readers!
Welcome to the second installment of our article series dedicated to the theory and practice of defending against prevalent attack patterns in software development.
In this very segment, we will explore the ins and outs of the Server-Side Request Forgery (SSRF) threats, and come to know why we, developers, should be concerned about it.
By the end of this paper, you will be well-equipped with both the general knowledge about SSRF attacks and skills needed to diminish their impact on your applications.
So without further ado, let’s begin our journey…
Understanding SSRF
“In a Server-Side Request Forgery (SSRF) attack, the attacker can abuse functionality on the server to read or update internal resources. The attacker can supply or modify a URL that the server-side code will read or submit data to.
By carefully choosing the URLs, the attacker can read configuration such as server metadata, connect to internal services like http-databases or perform POST requests towards internal services not intended to be exposed”.Excerpted from: https://owasp.org/www-community/attacks/Server_Side_Request_Forgery
In other words, during an SSRF attack, a malicious actor aims to take advantage of the system's capability to generate unauthorized (i.e. "forged") requests on behalf of a vulnerable application. These harmful requests can target both internal services and external systems and, because they appear to originate from the application itself, are often indistinguishable from legitimate ones.
Hence, they can bypass most of the established security measures, letting attackers succeed in their exploit.
In essence, any software service able to load external data, reference public-facing links or access third-party APIs may be susceptible to SSRF. The reason is that consumers of such services can initiate malicious requests and manipulate the ensuing responses at their discretion.
Given the prevalence of modular architecture in modern applications, SSRF vulnerabilities are becoming rather widespread, nonetheless remaining very dangerous.
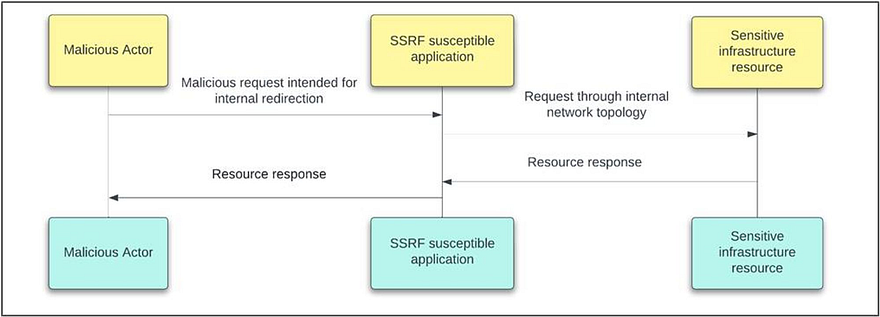
A Sequence diagram showing the general process behind a targeted SSRF attack
In most cases, the SSRF requests are intended to scan the internals of a certain software system, thus putting its stability and resilience at a significant risk. With this, an attacker aims to discover the service's infrastructure or sensitive administrative resources that are generally inaccessible otherwise (like configuration manifests or environment variables). While these resources are indeed hidden from consumers` eyes by a complex network and/or cloud topology (like Service Meshes or mTLS), they still may be accessed by the application.
On the other hand, SSRF requests can as well be used to compromise the service's external integrations (e.g. Payment Gateway), or even force applications to serve as a conduit for launching attacks on other systems.
And, with the increasing popularity of event-driven Webhooks as a service-to-service communication mechanism, attacks of this type are becoming widespread.
Post Scriptum
While some security researchers don’t consider SSRF a full-valued “attack” (as it is relatively easy to identify and typically does not require prior planning to get done right), at the time of writing this article (November 2023), the Server-Side Request Forgery firmly holds a place among the most dangerous attack patterns.
Two years ago, back in 2021, the well-known OWASP “Top Ten” project placed the SSRF threat 10th in a list of the most prevalent web application security risks.
And in late 2023, it was promoted to the 7th spot, which shows that this seemingly intuitive threat is rapidly becoming a Leviathan that must be taken care of.
Real-World Example
To better grasp the theoretical concepts, let’s walk through a legitimate scenario.
For instance, think of an emerging social network that allows its users to add a profile picture, either by directly uploading it or providing a resource URI from elsewhere on the internet. Regardless of the chosen upload variant, the application stores the image link within the underlying data storage service (using a direct URI if provided, otherwise gets one from object storage).
The team behind the project decided to enforce a strict SFW content policy, hence the provided image is subjected to initial moderation before actually appearing on a person’s page. This process includes a visual analysis and exclusion of any inappropriate or offensive content, performed by a third-party service like “Amazon Rekognition”.
However, the application’s upload mechanism does not actually verify the authenticity of a provided origin, nor checks the content type that such request is expected to respond with. And, without such preventive measures, any user effectively takes full control over the provided URI parameter.
So, under normal circumstances, a user-given URI may link to the popular image providers like “Unsplash”, as to the reliable services that won’t cause any harm upon subsequent requests. On the other hand, a malicious actor can intentionally submit an unexpected URL (e.g. “http:// 165.163.12.2/admin”) that points to the administrative server instance that application has access to.
The request to such a URL forces the application server to unknowingly make a harmful request that leads to the exposure of software’s internal structure and the leakage of sensitive data to an attacker. It is also possible to perform arbitrary “GET” requests to any external domain or IP address, including those on the local network, and to resources on the server that hosts the vulnerable application (i.e. localhost).
SSRF Classification
SSRF against the local server — An attacker tricks an application into performing a request to the server it is hosted on, typically via its loopback network interface. This often involves providing a URL with a hostname such as
localhost,127.0.0.1or2130706433(integer representation).SSRF against the internal infrastructure — An attacker leverages the requesting functionality to discover the hidden internal services that an application has access to. He then manipulates it to perform malicious requests to the newfound targets, gaining unauthorized access to the software system’s core.
SSRF against the external systems — An attacker utilizes the third-party integrations application relies on for correct functioning. These services frequently employ non-routable, private IP addresses and rely on the network topology for protection. As a result, their security measures are often less robust and can be “easily” bypassed if discovered. After discovering exploitable SSRF vulnerabilities, a malicious actor crafts the service-specific malicious requests that can cause substantial financial and reputational losses.
In turn, each attack may be executed in one of three ways:
Classic SSRF: Involves direct requests to the system’s internal resources.
Blind SSRF: The attacker doesn’t directly see the response, but can nonetheless infer success or failure based on application behavior.
Collaborative SSRF: Requires careful planning and utilization of complex techniques such as DNS rebinding or exploitation of specific protocols.
The SSRF Threat in Microservice Architecture
Because SSRF is a request-based attack pattern, it thrives in conventionally stateless environments that largely depend on external systems for proper functioning.
By design, the microservice architecture propagates software systems composed of many small, independent services communicating with each other. Because of their modular nature, microservice applications are wide open to an array of possible attack vectors, formidably, for the SSRF itself.
Having established that, here are some key points to consider:
Service-to-Service Communication: Microservices often communicate with each other over the private network topology. If one microservice is vulnerable to SSRF, the attacker can attempt to make unauthorized requests to other internal microservices on its behalf. This can lead to system-wide information disclosure, functionality disruption, or even unregulated access to sensitive data.
Impact on Downstream Services: A SSRF attack on a microservice can have a cascading effect on downstream services. For instance, if a compromised microservice can access a database, it may attempt to manipulate or extract data from that database.
Security Boundaries: You should clearly define the required security boundaries between microservices. Implement regulated authentication & authorization mechanisms, ensuring that each microservice only has access to the resources it needs and nothing more. Additionally, consider employing granular rate-limiting strategies depending on the functional requirements of a specific service.
With this, the potential damage caused by a successful SSRF attack can be greatly reduced.Network Segmentation: This point is particularly crucial in a microservice architecture. By segregating your internal network into multiple distinct segments, you can restrict the attacker's ability to laterally move between microservices even if SSRF bursts in one of them.
Monitoring and Incident Response: Implement robust monitoring for inter-service communication. Detect unusual patterns or unexpected requests between microservices, which could indicate an SSRF attack. Establish an incident response plan to quickly identify, contain, and mitigate the impact of SSRF incidents in a microservices environment.
The SSRF Threat in Cloud Environments
If you're deploying an application stack to a semi-managed cloud environment (like Amazon Web Services), you should always inspect and properly configure any host-revealing features that a specific platform provides.
For example, AWS has an "Instance Metadata Service" (abbr. IMDS), that exposes valuable details about an EC2 instance - such as instance ID, public IP address, IAM role and other sensitive information.
While such insights may indeed be useful for the infrastructure maintainers, they also appear rather relevant for the attackers.
NB: Other widely-recognized cloud behemoths also provide similar services:
Microsoft Azure - Instance Metadata Service.
Google Cloud Platform - VM Metadata Server.
In the context of SSRF, if a malicious actor forces a VPS to request the metadata service, he may acquire the private operational data and further escalate the attack.
Of course, Amazon, being the leading cloud solutions provider has already implemented proper security measures to mitigate such risks.
It introduced the next generation of IMDS service called "IMDSv2".
This version includes protections against SSRF attacks by requiring a session token obtained through a secure handshake process.
By configuring all your EC2 instances to use the v2 of IMDS, you can ensure that the attackers cannot obtain access to the configuration settings of an underlying VPS.
Defense Strategies
Here, we need to agree upon one important fact: to properly mitigate SSRF-posed vulnerabilities, our application shouldn’t trust any given source — not even its internal infrastructure itself. Each incoming URL must be verified and checked against a blacklist, and every outcoming redirection must be inspected before actually making a request.
1. Employing URL Validation Policy.
To successfully hinder the SSRF attack consequences, we should find the means to identify the unexpected URL patterns and block their initial processing. The first idea that always comes to mind when we use the verbs “identify” and “block” in a security context is the proper validation of any user-provided input.
Precisely with SSRF, the existing Input Validation policy may be additionally extended to process any user-provided URLs and links (including generic domain names and IPv4/IPv6 addresses). In such a way an application becomes capable of detecting and blocking malicious requests before they can affect the business logic.
When implementing such an algorithm, we should first consider whether the provided URL is a domain (host) name or just an IP address.
1. If it is a Domain.
Maintain a dynamic whitelist of trusted domains and block anything that it doesn't include. If your application only needs specific resources from a domain, consider restricting the access policy to their URLs. This restriction adds an extra layer of security to the general validation pipeline.
Inspect DNS address records (abbr. “A”) of any provided domain name.
Block the ones that resolve to the local loopback address (127.0.0.1).Blacklist any unexpected request schemas. Say, if your application only supports HTTP(S) communication, prohibit any other protocols from being used (like WS(S) ->
ws://, FTP ->ftp://or Gopher ->gopher://).[OPTIONAL] Additionally, you may perform an HTTP “HEAD” request to pre-check the
Content-Typeheader value against the permitted response types.
For example, if a URL must exclusively point to a static image resource, you can reject any MIME type other than image/jpeg, image/png, image/webp or image/x-icon (favicon format).
This security measure may not be necessary for all use cases and hence should be applied selectively.
2. If it is an IPv4 address:
Verify that the address is legitimate and is RFC 791 compliant.
Block the explicit IPv4 loopback addresses (127.x.x.x).
Block any IPv4 private addresses assigned from the following three reserved blocks, defined by the RFC 1918 specification:
10.0.0.0 ㅤ ㅤㅤ- ㅤ10.255.255.255 ( 10.0.0.0/8 prefix ).
172.16.0.0ㅤ ㅤ -ㅤ 172.31.255.255 ( 172.16.0.0/12 prefix ).
192.168.0.0ㅤ - ㅤ192.168.255.255 ( 192.168.0.0/16 prefix ).
These addresses can only be used within private networks and are conventionally not routable on the global Internet.Block an unspecified IPv4 address (0.0.0.0), as it may be exploited by attackers to target internal resources or proxy external network requests.
3. If it is an IPv6 address:
Verify that the address is legitimate and is RFC 2460 compliant.
Block the explicit IPv6 loopback addresses (e.g. [::1]).
Block any IPv6 Unique Local Addresses (ULA) assigned from the
c00::/7address block. The ULAs are defined by RFC 4193 and represent the IPv6 equivalent of a reserved IPv4 subnet pool from RFC 1918. These addresses can only be used within private networks and are not routable on the global Internet.[OPTIONAL] Block any addresses translated using Teredo, as attackers can leverage them to bypass implicit IPv4 restrictions.
NB: Only allow them if you intend to support URLs that leverage the IPv6 representation format.[OPTIONAL] Block the IPv4-mapped IPv6 addresses to reduce the attack surface. Any IPv6 address prefixed with “::ffff:” followed by a regular IPv4 address is considered an IPv4-mapped IPv6 address.
For example, “::ffff:192.168.1.1” is a representation of the IPv4 address “192.168.1.1”.
NB: Only allow them if you intend to support the dual-stack environments (simultaneous coexistence of IPv4 and IPv6 addresses).
2. Zero Trust — Reducing the Attack Surface.
To properly secure against SSRF attacks, we need to focus on all possible attack targets — not just the application level itself. With that, we also need to ensure that any vulnerable resources within our own infrastructure cannot be abused, or at least not as freely as they allow to by default.
We have already discussed that the internal resources are normally protected by the network topology, which means that they are assigned private, non-routable IP addresses, and are not directly accessible from the public Internet. However, taking into account all potential SSRF attack vectors, this fact alone is not enough to guarantee solid protection of the application’s infrastructure. We need to do more.
To establish a secondary layer of defense we can filter out the unauthorized traffic by implementing a strict authentication & authorization policy. Preferably, the one using role- or attribute-based access control (RBAC or ABAC), as well as adhering to the Principle of Least Privilege.
Most third-party infrastructure services like databases (SQL/NoSQL), network utilities (Load Balancers/DNS resolvers/CDNs) and logging & monitoring stacks (ELK/Prometheus-Grafana) do not enforce the authentication by default, as they assume existence within a secure protected environment.
Nevertheless, they all provide some form of authentication and authorization mechanism that can be leveraged to restrict the parties that access them. With authentication enabled, even if an application level is susceptible to SSRF attacks, it won’t be able to access the protected internal resources — much to the attacker’s pity.
3. Zero Trust — Disarming Blind Moles.
It is uncommon for any request-based attack patterns (including SSRF) to be executed blindly. This means that an attacker does not actually receive a response from the targeted vulnerable service, and hence cannot ensure whether his attack succeeded or not.
To further rub salt in his wounds, we can enforce the Rate Limiting strategies on both the application level and internal services level, effectively preventing the excessive usage of our requesting functionality.
On the application level, we the developers are responsible for implementing that functionality, making it more or less strict depending on the software’s non-functional requirements and the conducted vulnerability assessments.
As for the infrastructure level, we have a situation similar to authentication: the majority of services our application relies on (such as API Gateways, Reverse Proxies/Load Balancers) provide a way to limit the number of requests issued by a certain individual within a specific time frame.
And, even if your application must allow users to assess the results of their requests, you should ensure that no insightful data is leaked within the response body. The external responses should never be forwarded to the client as is; instead, they have to be uniformly structured, briefly denoting whether an operation has succeeded or failed.
4. Zero Trust — Configuring the Firewall.
Firewall — a “mosquito net” keeping the street insects outside your apartment.
To identify and safeguard the internal infrastructure against zero-day SSRF vulnerabilities, our only solution is a proper Web Application Firewall (WAF) configuration. While its employment alone doesn’t completely eliminate the root cause, still, if well-configured, it solidifies the overall protection by making such SSRF attacks much harder to exploit.
In simple terms, WAF acts as a barrier between a web server it is installed on and the public Internet, monitoring and filtering any in- or outcoming network traffic based on a set of pre-defined rules. By leveraging its vast threat intelligence network, a firewall can help you prevent most of the common attack patterns, as well as save from more elaborated and planned out threats.
As a part of the WAF configuration, you can enable the blacklisting of sensitive files and endpoints. This allows to prevent attackers from leveraging the crafted URLs to read local configuration manifests or access debugging endpoints. The common targets include:
/proc/self/cwd— Reveals the current working directory that may be used for determining the actual attack vector./etc/passwd— Contains detailed information about the OS accounts existing on the intercepted host machine./dev/randomor/dev/urandom— Can be abused to exhaust server entropy./var/run/docker.sock— Allows an attacker to control the launched Docker containers.Debugging or admin endpoints used by the server-side frameworks, application servers or third-party integrations.
5. Segmenting the Network Isles.
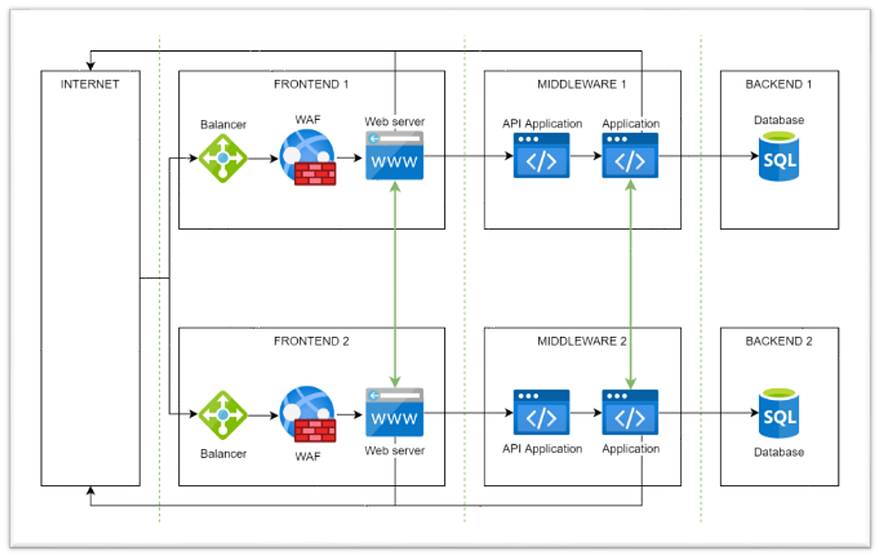
The component diagram displaying an internal service-to-service interaction in a multi-segmented infrastructure architecture.
Going deeper, you may also consider using a Network Segmentation strategy to segregate sensitive resources from the publicly accessible ones. It refers to the process of dividing a software’s internal network into multiple distinct segments that operate in different environments and may or may not exist separately from each other.
These segments (usually called “Segmented Zones”) are represented by dedicated subnets or virtual private networks. With this, each established zone comprises a set of internal infrastructure services, grouped by their levels of sensitivity, vulnerability risk and importance to the core application’s functionality.
By implementing this, you essentially create barriers that prevent unauthorized access to the critical infrastructure components. This approach is highly recommended to block illegitimate calls directly at the network level itself.
Here are six key procedures involved in implementing a Network segmentation:
Identification of Critical Resources: Determine which components of your infrastructure are particularly sensitive or critical, and must not be directly accessible from untrusted sources.
Segmentation of Internal Services: Establish segmented zones with different access policies within your network architecture. Place critical assets in a dedicated segment, isolated from less sensitive areas. Doing so essentially reduces the SSRF attack’s ability to discover and exploit valuable resources.
Segmentation of External Services: Assign any third-party services your application relies on to dedicated subnets or virtual networks separate from your internal network. Ensure that all external integrations are isolated from the internal ones, and can only bi-directionally communicate through secure, controlled traffic channels.
Deployment of Firewalls at Every Edge: Implement firewalls and access controls at the boundaries of each network segment. Configure these security measures to permit only necessary communication between the two controlled segments. Deny all unnecessary inbound and outbound traffic to minimize the attack surface.
Employment of traffic Access Control Lists: Implement Access Control Lists (ACLs) to specify which network interfaces or IP ranges within your internal network can communicate with the external services.
Zero Trust Model: By accepting a zero-trust security model we should assume that threats may exist not only outside our network, but also directly inside it. Having adopted such a model, you oblige every user and system, including those within the internal network, to authenticate and be authorized before accessing resources.
In this case, even if some internal service has been compromised, a successful SSRF attack won’t be able to spread across the whole system, and its overall negative effect will be minimized.
Moving Towards Practice
While most of the discussed mitigation mechanisms are performed on the network level and are not directly related to Node.js itself (i.e. any other similar environment), we can still demonstrate how to enforce the input validation policy described above.
To implement it, we will utilize the three popular NPM packages:
tldts— used to parse incoming URLs, extracting associated insightful metadata.is-valid-domain— used to verify the domain’s legitimacy of the provided URL.ip-address— used to verify the legitimacy of the provided IPv4/IPv6 addresses.
So, let us move on to the algorithm:
1. Defining a backlist of prohibited address ranges:
RFC 1918 private IPv4 addresses.
RFC 4193 private IPv6 addresses.
IPv4-mapped IPv6 addresses (starting with “:ffff:0:0”).
Unspecified (wildcard) addresses (0.0.0.0).
/* ip.ts */
import { Address4, Address6 } from 'ip-address';
// **RFC 1918** local (private) IPv4 address ranges
const rfc1918Ranges = [
new Address4('10.0.0.0/8'),
new Address4('172.16.0.0/12'),
new Address4('192.168.0.0/16'),
];
// **RFC 4193** local (private) Iv6 address range
const rfc4193Range = new Address6('fc00::/7');
const v4MappedIPv6 = new Address6('::ffff:0:0/96');
const unspecifiedIPv4 = new Address4('0.0.0.0/32');
...
2. Verifying the legitimacy of an IPv4 address:
...
function verifyIPv4Address(hostname: string) {
const parsed = new Address4(hostname);
if (!parsed.isCorrect()) return false;
// blocking loopback addresses (127.1 and 127.x.x.x)
if (parsed.address.startsWith('127.')) return false;
// blocking access to the unspecified network interface (0.0.0.0)
if (parsed.isInSubnet(unspecifiedIPv4)) return false;
// blocking any address from the conventional (RFC 1918) private ranges
for (const privateRange of rfc1918Ranges) {
if (parsed.isInSubnet(privateRange)) {
return false;
}
}
return true;
}
...
3. Verifying the validity of an IPv4 address:
...
function verifyIPv6Address(hostname: string) {
const parsed = new Address6(hostname);
// blocking Teredo addresses to avoid bypassing IPv4 restrictions
if (!parsed.isCorrect() || parsed.isTeredo()) return false;
// blocking IPv6 loopback
if (parsed.address.startsWith('::1')) return false;
// blocking IPv4-mapped V6 addresses
if (parsed.isInSubnet(v4MappedIPv6)) return false;
// blocking ULAs (Unique Local Addresses)
return !parsed.isInSubnet(rfc4193Range);
}
4. Composing the previous steps:
...
export function isValidIpAddress(hostname: string): boolean {
try {
return verifyIPv4Address(hostname);
} catch {
// if the address is not IPv4 based,
// inspect its IPv6 representation
return verifyIPv6Address(hostname);
}
}
— — — — — — — — — — — — — —
5. Verifying the domain legitimacy:
/* domain.ts */
import isValidDomain from 'is-valid-domain';
export function verifyLegitimateDomain(hostname: string): boolean {
return isValidDomain(hostname, {
wildcard: false,
subdomain: true,
allowUnicode: false,
topLevel: false,
});
}
6. Define a whitelist of allowed origins:
/* verify-url.ts */
const whitelist = new Set([
'plus.unsplash.com',
'trusted-domain-1.com',
'trusted-domain-2.com',
// Other trusted domains here...
]);
...
7. Verifying the URL’s schema against the whitelist:
...
const defaultSchemas = ['https:', 'wss:'];
function matchesSchema(
schema: string,
allowedSchemas: Array<string> = defaultSchemas,
): boolean {
const wildCards = allowedSchemas.map((s) => s.split('*')[0]);
return wildCards.some((wildcard) => schema.startsWith(wildcard));
}
...
8. Composing all checks together:
...
import { parse } from 'tldts';
import { isValidIpAddress } from './ip';
import { verifyLegitimateDomain } from './domain';
function safeParseUrl(url: string) {
return parse(url, {
detectIp: true,
validateHostname: true,
allowPrivateDomains: false,
});
}
async function verifyContentType(allowed: Array<string>): Promise<boolean> {
const { headers } = await axios.head(userProvidedUrl, {
signal: AbortSignal.timeout(200),
});
const actualContentType = headers['Content-Type'];
return allowed.includes(actualContentType);
}
declare type RequestSchema = `${string}${':' | '*'}`;
declare type ExpectedSchemaUrl = `${string}://${string}`;
export function verifySafeUrl(
userProvidedUrl: ExpectedSchemaUrl,
allowedSchemas?: Array<RequestSchema>,
): boolean {
// reading the URL's schema
const [urlSchema] = userProvidedUrl.split('//');
// comparing it with the list of allowed schemas
if (!matchesSchema(urlSchema, allowedSchemas)) {
return false;
}
// safely parsing the provided URL
const { hostname, isIp } = safeParseUrl(userProvidedUrl);
const hostName = hostname as string;
try {
// [optional] perform an HTTP `HEAD` request to verify
// that `Content-Type` header is legitimate
// if (!await verifyContentType([...])) return false;
// handling IP/domains separately
if (isIp) {
return isValidIpAddress(hostName);
}
const isDomainLegitimate = verifyLegitimateDomain(hostName);
return whitelist.has(hostName) && isDomainLegitimate;
} catch {
return false;
}
}
9. Blocking any domains that resolve to the loopback addresses family:
/* dns-resolve.ts */
import { resolve } from 'node:dns/promises';
import { URL } from 'node:url';
export async function doesResolveToLocalhost(url: string): Promise<boolean> {
try {
const { hostname } = new URL(url);
// resolving a provided hostname into an array of 'A' records
// (domain name -> IP address)
const resolvedIps = await resolve(hostname, 'A');
// verifying whether discovered IP-addresses point to the loopback
// (127.x.x.x)
return resolvedIps.some((ip) => ip.startsWith('127.'));
} catch {
return false;
}
}
— — — — — — — — — — — — — —
Now, we’re up to the testing:
import { verifySafeUrl } from './verify-url';
import { doesResolveToLocalhost } from './dns-resolve';
// TESTING
const userProvidedURLs = [
// whitelisted domain -> allowed
'https://trusted-domain-1.com/resource',
// non-whitelisted domain, unsupported schema -> disallowed
'ftp://ftp.example.com',
// RFC 1918 address, unsupported schema -> disallowed
'gopher://192.168.1.12/',
// IPv4 loopback addresses -> disallowed
'file://localhost/payments/annual_report.csv',
'http://127.0.0.1',
// unspecified IPv4 -> disallowed
'http://0.0.0.0/admin',
// Teredo-based attack -> disallowed
'wss://[2001:0:ce49:7601:e866:efff:62c3:fffe]:8080/',
// IPv6 loopback -> disallowed
'http://[::1]',
// image resource from trusted domain -> allowed
'https://plus.unsplash.com/premium_photo-1674506654119-28356186d88f?&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D',
];
;(async () => {
// the domain name below **always** points to the **localhost**
// refer to the [[https://readme.localtest.me/]]
const domain = 'http://redirecttest.localtest.me';
const isLoopback = await doesResolveToLocalhost(url);
if (isLoopback) {
console.log(`The domain ${domain} does resolve to localhost.`);
} else {
console.log(`The domain ${domain} does not resolve to localhost.`);
}
})();
console.time('mark');
userProvidedURLs.forEach((url) => {
console.log(`URL --- ${url} ---`);
const isSafe = verifySafeUrl(url, ['https:, ws*']);
console.log(`Status: ${isSafe}\n`);
});
console.timeEnd('mark');
Conclusion
In this part of our series, we have deeply dived into the world of Server-Side Request Forgery threats. This study has provided us with a solid understanding of this attack pattern. We have also gained extensive knowledge on mitigation mechanisms that allow us to keep such threats away.
Please keep in mind that countermeasures described here are imperfect on their own, and require their application-specific combination to serve as a reliable layer of defense. With this, you are now well equipped to secure any server-side applications, as well as to continue exploring the intricacies of SSRF on your own.
Stay vigilant, validate inputs rigorously, and embrace a holistic approach to server-side security.
Additional Resources
For further exploration of CSRF prevention and security best practices, you may refer to these external resources:
In the next article…
Very soon, we will continue to enhance our comprehension of the prevalent attack patterns within the domain of web security. In particular, we shall delve into fundamental principles of Cross-Site Scripting (XSS) — one of the most notorious injection-based threats.
If that sounds interesting, stay tuned for further updates!
Until then, stay secure and happy coding!



